Una de las técnicas más utilizadas dentro del análisis predictivo son los árboles de decisión. Esta técnica tiene múltiples aplicaciones en el campo de la estadística, pero nos vamos a centrar en su uso para realizar predicciones, concretamente obtener probabilidades de eventos. En este post revisamos una posible forma de hacerlo con el software de uno de los principales fabricantes del software de business analytics: SAS (www.sas.com)
- Proceso predictivo guiado en SAS/Visual Analytics
- Construir modelo de forma guiada en SAS/Enterprise Miner
- Realizarlo con el módulo SAS/IML (macro treedisc)
- Realizarlo con el módulo SAS/OR (proc dtree)
- Realizarlo en código BASE con procedimientos SAS/STAT (Entorno Enterprise Guide)
En caso de hacerlo en Miner el modelo generado en Miner podría ser posteriormente ejecutado en Enterprise Guide utilizando la tarea de Data Mining -> Model Scoring.


res: respuesta a la campaña (1: redención, 0: sin redención)
id_cliente: código de cliente
edad: edad del cliente
compras_3m: número de compras realizadas en los últimos 3 meses
compras_12m: número de compras realizadas en los últimos 12 meses
tipo_cliente: Tipo cliente por canal principal de compra (W: web, T: tienda)
Para obtener el modelo dividimos la tabla que contiene el histórico de campañas (100k) en dos tablas una para entrenar el modelo (test) y otra para validarlo (validar).
data test validar;
set campañas_hist;
if _N_ < 70000 then output test; else output validar;
run;
Aplicamos el procedimiento hpsplit, la variable a predecir es res (respuesta a la campaña) y las variables predictoras son: tipo_cliente edad compras_3m compras_12m
proc hpsplit data=test maxdepth=4 maxbranch=2 nodestats=arbol; /* nodestats guarda el arbol */
target res_campaña; /* variable a predecir */
input tipo_cliente edad compras_3m compras_12m; /* variables en base a las q predecimos */
code file="%sysfunc(pathname(work))/model_dtree.sas"; /* guarda el modelo construido */
rules file="/home/juanvg1972/ficheros/rules_dtree.txt"; /* reglas aplicadas */
output importance=imporvar; /* importancia de cada variable */
run;
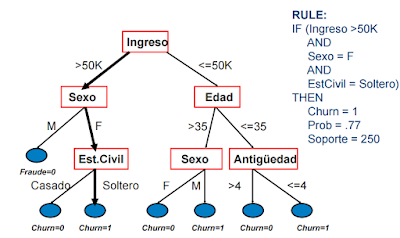
En la tabla arbol guardamos el arbol de decisión obtenida:

Podemos ver la importancia de cada variable que hemos guardado en la tabla imporvar
proc print data=imporvar (keep = itype tipo_cliente edad compras_3m compras_12m);
run;

Para visualizar gráficamente el arbol creado, empleamos el procedimiento netdraw que nos permite obtener una representación rápida, pero visualmente no es el más óptimo. Hay otras opciones para visualizar el arbol:
- Calcular el layout del arbol y pintarlo con proc sgplot
- Pintar la salida del fichero plaño rules_dtree.txt con una herramieta tipo GraphViz
- Generar arbol interactivo en SAS/GRAPH (ds2tree macro)
data arbol_or;
length parent_or id_or $2. desc_node $20.;
set arbol;
if parent = . then parent_or = 'OR'; else parent_or = parent;
id_or = id;
desc_node = strip(splitvar||'-'||decision); /* construimos el campo descriptivo que queremos visualizar */
run;
proc netdraw graphics data=arbol_or;
actnet / act=parent_or
succ=id_or
id=(desc_node)
nodefid
nolabel
pcompress
centerid
tree
arrowhead=0
xbetween=3
ybetween=2
rectilinear
carcs=black
ctext=white
htext=1;
run;
Una vez visualizado el arbol, lo aplicamos a la tabla validar para evaluar su capacidad predictiva.
data validar_res;
set validar;
%include "%sysfunc(pathname(work))/model_dtree.sas";
run;
En los campos P_res_campaña1 (prob res = 1) y P_res_campaña0 (prob res = 0) obtenemos la probabilidad de respuesta a la campaña.

Para validar el nivel de acierto del modelo podemos hacer una validación cruzada:
data validar_res1;
set validar_res;
if P_res_campaña1 >= 0.5 then res_campaña_p = 1;else res_campaña_p = 0;
run;
proc sql;
create table tabla_valid as
(select res_campaña, res_campaña_p, count(*) as conteo
from validar_res1
group by res_campaña, res_campaña_p);
quit;

El modelo definitivo una vez realizados los pasos e iteraciones necesarias para la depuración del modelo se aplica sobre el target de clientes de la campaña actual.
Este ajuste que hacemos sobre el target, permite rediseñar el target optimizando la probablidad de respuesta. Posteriormente a la ejecución de la campaña se realiza una comparación de probabilidad con la realidad











